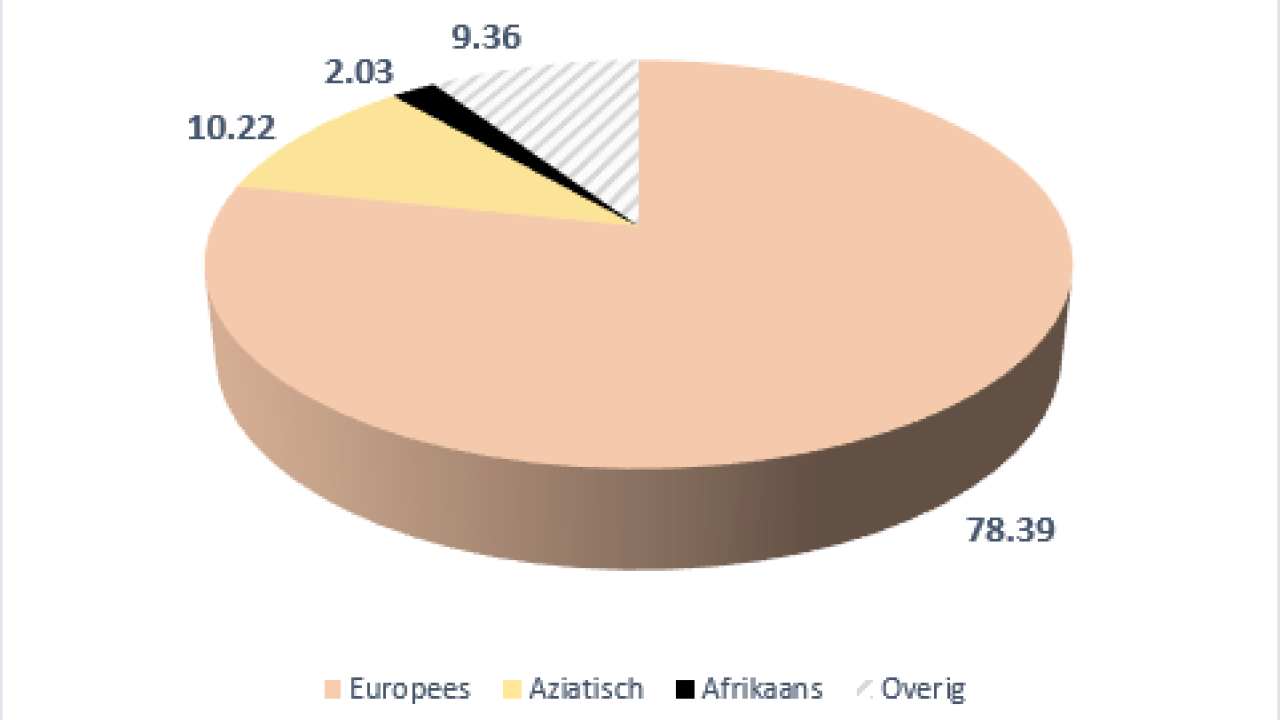
Zelfs het bepalen van de geografische herkomst slaagt redelijk, maar dan vooral op continentale schaal. Zo zijn Europese, Zuid-Aziatische, Oost-Aziatische, Sub-Sahara-Afrikaanse en inheems-Amerikaanse genetische componenten goed van elkaar te onderscheiden. Maar het wordt lastiger als je onderscheid wilt maken tussen bijvoorbeeld Scandinavische en Noordwest-Europese genetische componenten; dat geldt zeker ook voor variatie binnen Sub-Sahara-Afrika.
Ondanks de grote populariteit van de testen schiet de gebruikte technologie dus simpelweg tekort om het complexe vraagstuk van verloren Afrikaanse wortels op te lossen. Helaas zijn er op dit moment nog geen betrouwbaardere, niet-commerciële alternatieven beschikbaar.
De potentie van nieuwe technologie
Om genetische verschillen binnen continenten goed te kunnen analyseren zijn een miljoen genetische varianten onvoldoende. Het is als zoeken naar spelden in een gigantische hooiberg; om deze spelden te vinden zijn andere technologieën meer geschikt. Sinds een aantal jaar is het mogelijk om bijna alle drie miljard DNA-moleculen uit te lezen voor minder dan duizend euro; deze technologie wordt whole genome sequencing genoemd. De meest gangbare technologieën doen dit door het DNA in kleine stukjes van honderd tot enkele honderden aaneengeschakelde moleculen te knippen en deze vervolgens uit te lezen.
Sinds kort zijn er echter ook technologieën die veel langere kettingen van moleculen (duizenden tot tienduizenden) tegelijk kunnen uitlezen. Deze technologie, long-read sequencing genoemd, is door het gerenommeerde vakblad Nature uitgeroepen tot methode van het jaar 2022. Met deze technologie kunnen ook moeilijker uit te lezen gebieden van het DNA — met veel herhalingen — worden geanalyseerd; dat was met de gangbare technologieën niet mogelijk. Juist deze regio’s van het DNA vertonen veel variaties en zouden van belang kunnen zijn om verschillende populaties binnen continenten te onderscheiden. Bovendien biedt long-read sequencing de mogelijkheid om verschillende genetische variaties aan elkaar te koppelen. Deze gekoppelde variaties (haplotypen) zijn informatiever dan de op zichzelf staande variaties. Als je zoekt naar spelden in hooibergen, dan kun je elke hooiberg maar beter zo nauwkeurig mogelijk in kaart brengen Long-read sequencing biedt die mogelijkheid.
Onvoldoende referentiedata
Het Afrikaanse continent is vaak een ondergeschoven kindje: het is het minst ontwikkelde van alle continenten. De grootmachten op het wereldtoneel zijn meer geïnteresseerd in het verzamelen van de natuurlijke rijkdommen dan in het bestrijden van de armoede of het verhogen van de levensstandaard van de bewoners. Wat dat betreft is de wetenschap geen uitzondering: sinds jaar en dag richt genetisch onderzoek zich vooral op mensen met een westerse achtergrond. Ook in Azië is dit type onderzoek sterk in opkomst, maar kennis over genetische variatie binnen het Afrikaanse continent is nog steeds erg beperkt. En dat terwijl de genetische variatie in Afrika — de bakermat van de menselijke soort — juist groter is dan waar dan ook ter wereld. Afrika herbergt honderden of zelfs duizenden verschillende etnische groepen en er worden meer dan duizend verschillende talen gesproken.



Reacties
17 augustus 23
Dolf Evenberg
Afrikaans DNA
Beste Arwin,
Ik heb niet echt kritisch je bovenstaande verhaal/pleidooi gelezen. Zo bij een eerste lezing vind ik het een goed en duidelijk verhaal. Maar ik ben bevoordeeld, ik ken je en ik begrijp waar je het over hebt.
IK neem aan dat je met long-read whole genome sequencing ook onderscheid kunt maken tussen XXY, XYY, XX en XY.
Genen ?, sekse en gender. Is er sprake van een bepaalde wiskundige/statistische verdeling? Is deze verdeling continentaal invariant of is er sprake van verschillen in de verdeling?
Beste Arwin, ik wens je heel veel succes met dit mooie werk.
Met vriendelijke collegiale groet,
Dolf
18 augustus 23
Arwin Ralf
XY
Beste Dolf,
Altijd leuk om van je te horen en dank voor de succeswens. Je vraag over de geslachtschromosomen is interessant, maar niet direct relevant in de context van het onderzoek dat ik graag zou willen doen. XXY (Klinefeltersyndroom) en XYY-syndroom zijn beide vrij zeldzaam (~0.1 procent van de populatie). Dus zelfs als we dit tegen zouden komen, dan zal dat niet vaak genoeg zijn voor een steekhoudende statistische analyse.
Hartelijke groet,
Arwin
12 november 24
Marilou
Aanmelding DNA-onderzoek
Beste Ralf,
Ik kwam jouw naam tegen doordat ik onderzoek ging doen naar een wat uitgebreider dna-onderzoek naar mijn Afrikaanse voorouders. Zou je mij kunnen vertellen waar ik de plannen van dit nieuwe dna-onderzoek kan volgen en waar ik me hiervoor kan inschrijven, voor bijvoorbeeld een wachtlijst?
Alvast dank.
18 november 24
Arwin Ralf
Re: Aanmelding DNA-onderzoek
Beste Marilou,
Dank je voor je reactie. De handigste manier om op dit moment de ontwikkelingen te volgen is door mij toe te voegen op LinkedIn. Daar kunnen we ook makkelijk 1 op 1 verder praten.
Hartelijke groet,
Arwin